|
14.06.2015 Есть идея!
Анализ данных в школе: давайте поиграем в цифры
В статье исследуются подходы к статистическому анализу данных, получаемых в результате деятельности образовательного учреждения. Рассматриваются основные ошибки, возникающие в ходе анализа данных, приводятся примеры алгоритмов, потенциально интересных для проведения исследования различного рода мониторингов.
Один из первых вопросов, который задаёт ребенок — вопрос «Почему?». Любой родитель малолетнего первооткрывателя со вздохом выносит в мусорное ведро не одну разобранную до винтика и уже не поддающуюся возврату в исходное состояние игрушку. Со временем, под влиянием неких «темных сил» это желание куда-то исчезает, сложность объектов, которые мы наблюдаем во взрослой жизни завораживает и включает мощный механизм защиты, выражающийся к стремлению к тщательной отработке своей собственной, маленькой грядки. Азимов, сравнивая науку с огромным садом написал: «Ныне сад науки чудовищно велик — он покрыл весь земной шар, карта его так и не составлена, и нет такого человека, который бы знал о нем все.[…] И в самом саду науки каждый наблюдатель льнет теперь к собственной, изученной до последнего листочка и любимой кучке деревьев. Если иногда он и глянет в сторону, то обычно при этом виновато вздохнет».
К чему здесь это цитирование и разговор о поведении ребёнка? Посмотрите на школу: это ученик, родители, педагог. А сколько вопросов: как идет процесс обучения у ребенка, какие составляющие наиболее важны, чтобы получить хороший отзыв родителей, какие меры нужно предпринять, чтобы повысить уровень образования в существующих рамках? Посмотрите, а ведь это новая «игрушка»! Почему и как она работает — вот в чём вопрос. И у человека, сохранившего задор и смелость ребёнка не может не возникнуть желание задать тысячи «почему».
Хорошо, а где та отвертка и набор ключей, которые смогут нам разобрать всё до винтика и удовлетворённо откинуться в уютном кресле? Интуиция и жизненный опыт? Пожалуй нет. Не на сто процентов. Часто интуиция, особенно в современном мире, даёт масштабный сбой. И тогда на помощь приходят цифры. Таблички, которые в массовом порядке заполняет директор, завуч, учитель.
И вот беда, возник дикий диссонанс между тем, что происходит за пределами нашей родины и внутри. Посмотрите на названия статей, касающихся анализа данных как работы в англоязычных источниках: «Data Scientist: The Sexiest Job of the 21st Century», «The Sexiest Job of the 21st Century: Data Analyst», «For Today’s Graduate, Just One Word: Statistics».
На отечественных форумах и блогах мы видим совершенно другую ситуацию. Вот один из отзывов, который можно рассматривать как обобщение всех прочих: «Хочется крикнуть словами горьковского героя: „Дайте вздохнуть… вздохнуть дайте!“. Нам мучительно не хватает „свободы и покоя“. Нельзя оценивать качество педагогической деятельности по документам, потому что время, потраченное на их изготовление, отнято у ребенка».
В этой выдержке вся проблема: аналитическая деятельность, связанная со школьной статистикой, не является профильной, она нужна только для того, чтобы показать результат, но по документам (отчётам) судить о результатах нельзя. То есть — существует неудовлетворенность, связанная с применимостью получаемых в результате документов к принятию решений. Почему это происходит? Мы начали разбираться в вопросе.
Поиск в открытых источниках дал солидный урожай отчетов по теме мониторингов удовлетворенности, к сожалению в большинстве своем без какого-либо сырья.
Найденные в сети методики оценки удовлетворенности родителей удивили и вызвали некоторую оторопь. Практически все они построены по принципу работы с ранговой шкалой и заканчиваются следующей фразой: «Удовлетворённость родителей работой школы определяется как частное от деления общей суммы баллов всех ответов родителей на общее количество ответов». Давно и прочно доказано, что в случае оценок в баллах расчет среднего значения просто недопустим: да, это легко выполняемое в электронных таблицах действие, но оно дает неправильные результаты (есть мнение, что сумма большого количества переменных, измеренных в ординальной шкале дает интервальную шкалу, но это тот случай, когда исследователи до сих пор находятся в состоянии клинча). Однако, посмотрим на сами утверждения, которые требуется оценивать (выделение — авторы):
1. Класс, в котором учится наш ребёнок, можно назвать дружным.
5. В классе, в котором учится наш ребёнок, хороший классный руководитель.
6. Педагоги справедливо оценивают достижения в учёбе нашего ребёнка.
11. Педагоги дают нашему ребёнку глубокие и прочные знания.
Вопрос: при оценке школы дружность класса и знания равнозначны? Есть подозрения, что нет. Однако, сама методика агрегации данных говорит — да, с точки зрения удовлетворенности родителями работой образовательного учреждения эти критерии равнозначны. Но почему?
Теперь посмотрим на саму формулировку вопросов: согласно требованиям к опросному листу формулировки должны быть ясными и точными. Справедливость оценки и «хорошесть» классного руководителя в глазах родителя — вещь весьма субъективная, нет единой точки отсчета для всей группы отвечающих.
Однако представьте, какой отличный массив данных можно получить в результате, если подправить опросный лист. При применении корректных процедур анализа можно получить и знание того, что есть и того, на что необходимо воздействовать, чтобы получить лучший результат.
Следующий пример — «Отчет по результатам степени удовлетворённости участников образовательного процесса качеством образования» (название приводится в авторском исполнении). Автор выбрал табличное представление результатов. Схема документа: Общее описание → Таблица→ Описание результатов (часто неявное по отношению к таблице) → Обобщение → Выводы.
Рассмотрим одну из составляющих отчета: результаты анализа удовлетворенности учащихся школьной жизнью. В документе они сведены в одну таблицу:
Таблица 1
| Название | Группа вопросов 1 | Группа вопросов 2 | Группа вопросов 3 | Группа вопросов 4 | Показатель степени удовлетворенности | | ОУ1 | 8,1 | 5,2 | 6,5 | 3,7 | 5,8 | | ОУ2 | 4,1 | 3,5 | 3,4 | 1,9 | 3,2 | | ……… | ……… | ……… | ……… | ……… | ……… | | ОУ11 | 6,2 | 3,3 | 3,2 | 2,6 | 3,8 | | ОУ12 | 8,2 | 5,4 | 6,4 | 3,7 | 5,9 | | ОУ13 | 10,6 | 6,7 | 8,6 | 4,6 | 7,6 | | ОУ14 | 9 | 5,5 | 7,6 | 3,8 | 6,4 | | ……… | ……… | ……… | ……… | ……… | ……… | | ОУ17 | 4,1 | 3,5 | 3,8 | 3,4 | 3,7 |
Показатель удовлетворенности (последний столбец) судя по всему — среднее баллов по группам вопросов. При обработке выяснилось, что в ряде случаев имеют место ошибки округления (в десятых), а наличие мешанины в разделителях целой и дробной части чисел говорит о том, что расчёты, скорее всего, проводились вручную.
Давайте немного поиграем с таблицей.
Один из этапов исследования, который рекомендуется выполнять — оценка гомогенности, то есть групп, различающихся по характеристикам. Хорошим методом для оценки наличия групп является: построение диаграмм разброса и, в случае наличия подозрений на существование групп — кластерный анализ. Посмотрим на матрицу диаграмм по четырем группам опросника:
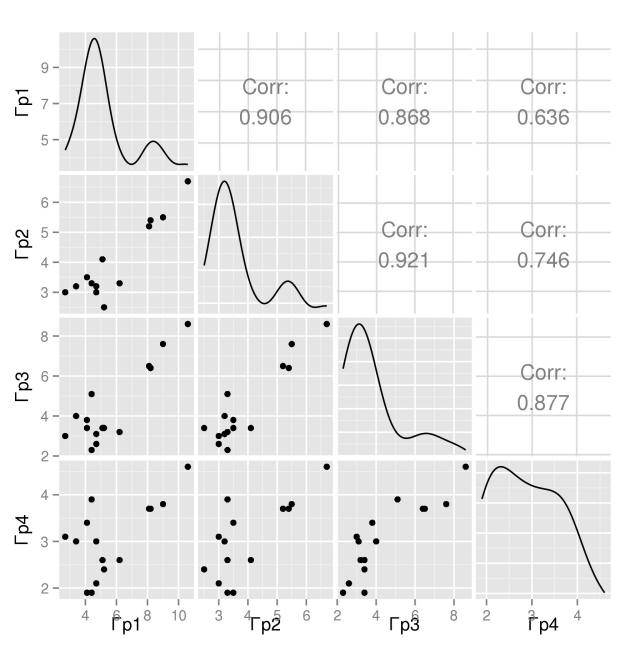
Рисунок 1
Ниже диагонали показаны диаграммы разброса по всем возможным комбинациям переменных, на диагонали — плотности распределений соответствующих переменных, выше диагонали — коэффициенты корреляции. Сразу обращают на себя внимание четыре точки, формирующие облако в правом верхнем углу каждой из диаграмм рассеяния и облако точек, прижимающееся к левому нижнему углу. Однако, на каждой из диаграмм — это одни и те же школы? Проведем кластерный анализ, в предположении, что в выборке существует две группы объектов.
Результат кластерного анализа: в выборке имеется четыре школы (ОУ1, 12, 13, 14) которые по всем показателям превосходят прочие — то самое облако в верхнем правом углу. Степень превосходства может быть оценена по последнему столбцу матрицы диаграмм. Обратите внимание на изменение коэффициентов корреляции — если раньше между переменными отмечалась сильная связь, то сейчас в основной группе из 13 школ ее нет, за исключением группы вопросов 3 и 4 (0.80). Если бы была понятна смысловая нагрузка переменных, то найденная связь могла бы быть проанализирована.
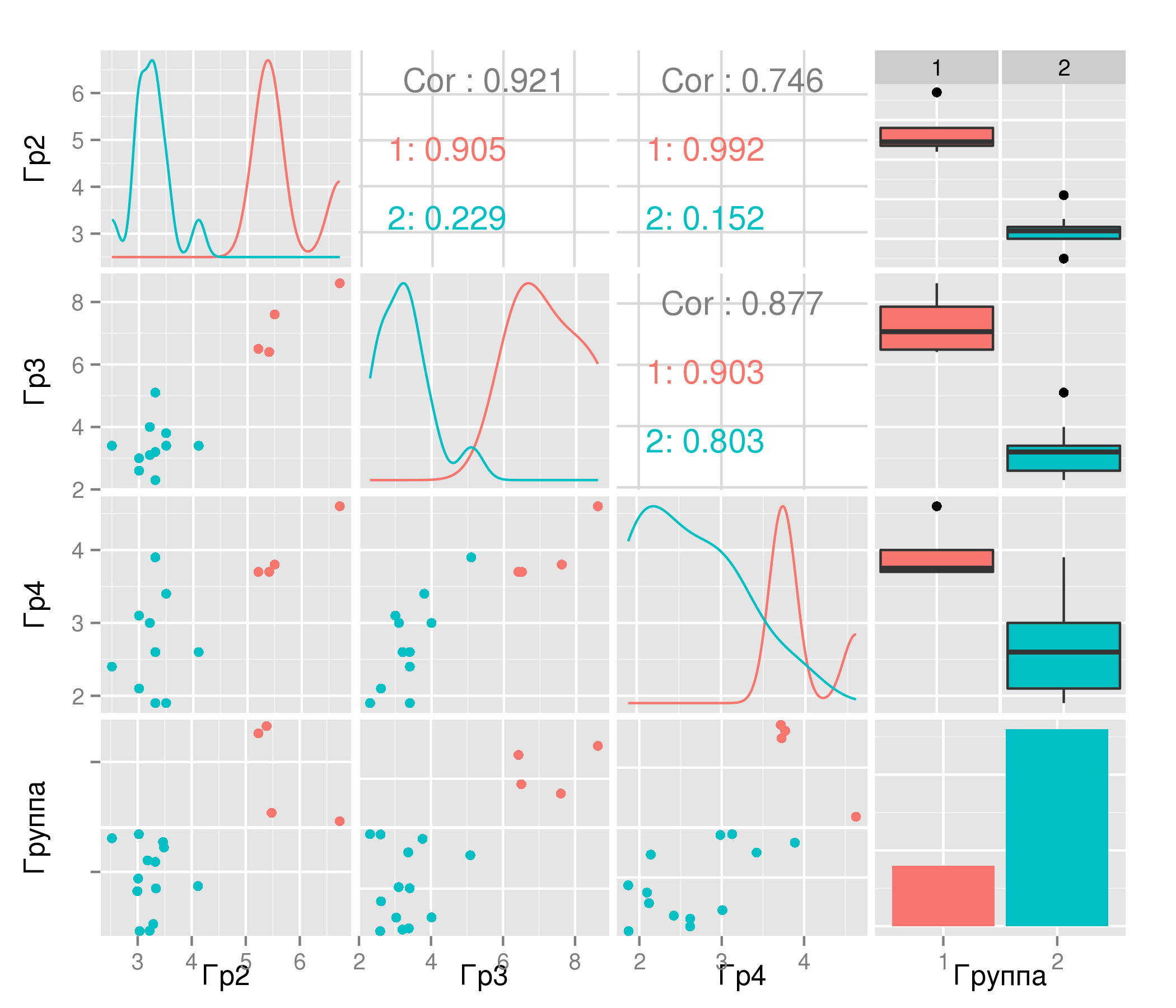
Рисунок 2.
Смотрите, что получается: есть группа лидеров, которые могут стать «драйверами роста». Что можно предложить в данной ситуации в качестве управленческого решения? Пристальнее присмотреться к этим школам и, возможно, начать
расповсюживание опыта.
Здесь же еще раз следует отметить, что среднее по группам вопросов вообще сыграло злую шутку с автором: удаление четырех школ с наиболее высоким баллом (уже знакомые ОУ1, 12, 13, 14) по группе вопросов 1 снизило среднее по школам практически на единицу с 5.5 до 4.5. Это тот самый случай, когда сумма температур по больнице, считая морг, стала равной 36.6. Ухудшены характеристики лидеров, но улучшены характеристики массы: и, как результат, среднестатистические рекомендации не удовлетворяющие никого.
Один из лучших документов, найденных в сети по данной тематике: «Мониторинг степени удовлетворённости участников образовательного процесса различными сторонами жизнедеятельности образовательного учреждения», разработанный силами специалистов одной из школ. В отличие от предыдущего рассмотренного документа основой для представления информации выбраны не таблицы, а диаграммы, что сразу приводит к невозможности работы с цифрами. Авторы выбрали схему: Общее описание → Диаграмма → Описание диаграммы → Обобщение → Выводы.
Остановимся на мониторинге удовлетворенности родителей. Изначально авторы приводят диаграмму, отражающую распределение родителей учеников по ступени обучения их детей.
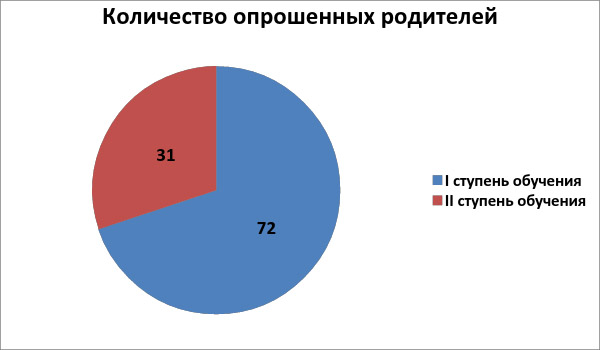
Рисунок 3
Диаграмма плохо интерпретируема: это проценты? Тогда почему сумма больше ста? Количество респондентов? Но всегда интересует вопрос о том, достаточно ли набрано ответов, чтобы распространять результаты на всех родителей. К сожалению из отчета это непонятно.
Описание диаграммы логично подводит к выводу о том, что родители учеников различных ступеней формируют две изолированных группы по поведению: «Таким образом, мы видим, что родители I ступени обучения приняли более активное участие в социологическом опросе. Это может объясняться тем фактом, что, во — первых,
в начальной школе родители чаще бывают в стенах образовательного учреждения, забирая ребёнка домой, во — вторых,
большей заинтересованностью, в — третьих, нельзя исключать вариант того, что не все обучающиеся предоставили родителям возможность участвовать в опросе (не принесли бланк анкеты)». При этом анализ обеих групп проводится совместно. Постойте, но раз они различны по активности, они же могут выделять и различные аспекты жизнедеятельности по разному. Веса отдельных компонент опроса могут быть различны. Как же проводить их анализ вместе?
Далее почти все диаграммы ставят при первом прочтении в
тупик, как приводимая ниже.
Так сложилось, что круговая диаграмма применяется в целях анализа одной переменной. Поэтому возникает когнитивный диссонанс: если на диаграмме показаны доли, то их сумма больше 100%, если количество ответивших, то оно в три раза больше показанного в начале количества, что и наталкивает на мысль о том, что в диаграмму сведены ответы на три вопроса. Остается открытым вопрос о том, что показано на диаграмме — доли или же проценты.
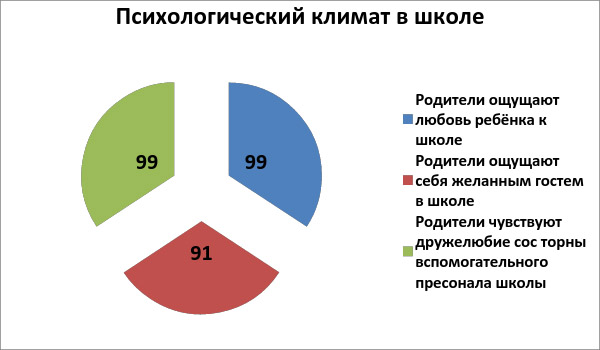
Рисунок 4
Остальной отчет выдержан в таком же духе, выводы относятся к текущему состоянию, но часть из них достаточно конкретна и исполнима силами самой организации.
Остальные работы, собранные под данный проект имеют те же характеристики, отличаясь лишь мастерством исполнения в части форматирования, диаграмм и таблиц.
Если обобщить результаты чтения отчетов, можно говорить о следующих чертах:
-
Однообразие статистических методов: сравнение долей, любовь к средним, которые неприменимы в большинстве случаев к получаемым данным. С другой стороны — полное пренебрежение к обязательным статистическим процедурам. -
Описательная статистика «первого уровня», без погружения в цифры, что косвенно подтверждает формализм исполнителей. Как следствие — формализм в выводах. -
Попытка сварить борщ из винограда, киви, свеклы на томатном соке: в общий котел сваливаются разные по весу вопросы, различные группы респондентов, что приводит к, возможно, приятным по цвету, но совершенно несъедобным результатам. -
В большинстве случаев нет динамики: ситуация рассматривается по одному году. -
Нет никаких указаний на достаточность выборки, при этом результаты обобщаются на уровень школы. -
Нет обобщающих вопросов: зачем додумывать за родителей: спросите об их оценке школы в целом. В прилагаемых опросниках этот вопрос почему-то не задается, хотя его наличие может дать огромные возможности по анализу данных. -
Отсутствует привязка к классам, предметам. Да, это серьезный уровень детализации, но ведь именно он даст возможность принять какие-то решения, не правда ли? -
Скучно. Поймите, анализ данных — это приключение, это получение знаний, которых еще не было. Это процедура, после которой вы можете сказать «Я прав, я могу доказать то, о чём я говорю». Формализм убивает.
На текущий момент порядок анализа достаточно хорошо отработан, как например в работе «A protocol for data exploration to avoid common statistical problems», Alain F. Zuur, Elena N. Ieno and Chris S. Elphick [1] и может быть вполне переложен на анализ данных в образовании. Работа по предлагаемому в статье протоколу, а также применение продвинутых статистических методов может принести большую пользу при анализе данных.
Рассмотрим еще один часто встречающийся пример: мониторинг обученности, проводимый по внешним тестовым заданиям. РЦОКОиИТ на условиях полной анонимизации предоставил результаты мониторинга обученности школьников 4, 9 и 11 класса по математике. Далее, в целях соблюдения политкорректности по отношению к авторам работ и снижения градуса напряжения будет проводиться максимальная очистка найденного от информации, позволяющей идентифицировать исполнителя.
Как подойти к анализу?
Если следовать ранее упомянутой работе, то порядок выполнения работы над данными должен быть следующим:
-
Формулировка гипотез, сбор данных -
Исследование данных 2.1. Проверка на выбросы по всем переменным 2.2. Гомогенность в отклике 2.3. Нормальность отклика 2.4. Частота неполных данных 2.5. Проверка наличия связей в объясняющих переменных 2.6. Оценка наличия взаимодействия межу объясняющими данными и откликом 2.7. Независимость в отклике -
Применение статистических моделей
Так как задача проведения полноценного исследования не ставилась, были выполнены лишь некоторые пункты, чтобы попробовать отыскать интересное, неявное и несколько отличающееся от привычного. В качестве вопросов были выбраны (да, хотелось поиграть с данными):
-
А есть ли физики и лирики? Разделены ли группы на тех, кому ближе русский язык и тех, кому ближе сухие числа? -
Такой «родительский» вопрос: а что по районам города и типам школ — есть ли различия?
Для анализа были выделены результаты работ по русскому языку у четвертого класса. Первое, что просто необходимо сделать — посмотреть на распределение результатов. И тут нас ждал сюрприз: выборка оказалась сильно скошенной в сторону лучшего результата: медиана равна 13, первая квартиль — 11 баллам. Это при том, что уже 12 баллов расценивались как четверка.
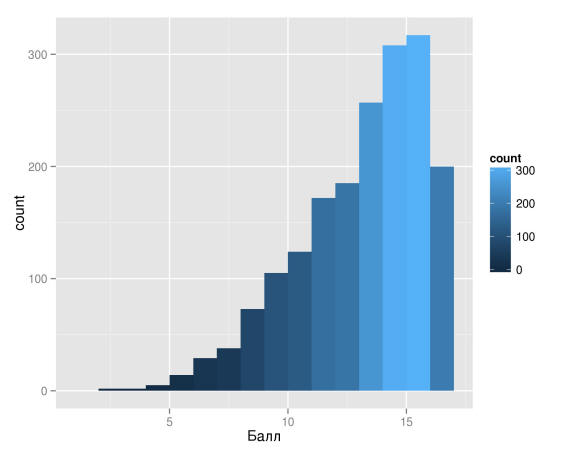
Рисунок 5
Вообще, логично было бы увидеть колоколообразную кривую, но тут ее нет. Ситуация с математикой ровно такая же, только с еще большим перекосом: первая квартиль уже равна 11, что соответствует 4 баллам. Сразу хочется обратить внимание, что при наблюдаемом типе ассиметрии (отрицательная ассиметрия) среднее будет всегда меньше медианы.
Теперь посмотрим на распределение по русскому языку и математике совокупно.
Гипотеза не оправдалась. Наибольшая плотность приходится на правый верхний угол, то есть дети массово сдают хорошо оба предмета.
При попытке ответа на второй вопрос (для разнообразия была взята выборка по математике, 11 класс, баллы теста переведены в пятибалльную шкалу) всплыл вопрос о достаточности выборки, так как по некоторым парам Тип ОУ-Район было выявлено достаточно небольшое количество школьников, сдававших тест. Однако, в попытке разобраться в положении дел был проведен анализ с помощью дерева решений.
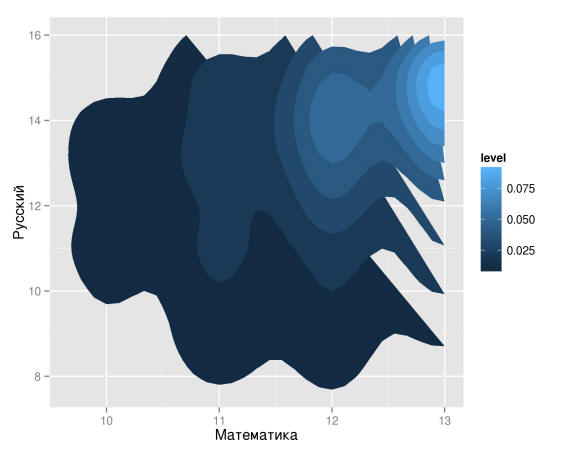
Рисунок 6.
Видно, что зависимость от района и типа ОУ есть. Предсказать результат на основе этого дерева нельзя, но то, что, допустим в ОУ типа 1, 4, 10 результаты различны и различия эти значимы для районов 4, 7 и районов 1, 2, 11, 14, 16 (узел 3) бесспорно: доля тех же «хорошистов» различается на 20%. Естественно, вывод будет иметь значение в случае достаточного объема выборки.
Честно говоря, страшно представить процедуру получения той же информации в случае обработки с помощью электронных таблиц. А здесь информация проста, понятна и доступна для принятия решений. 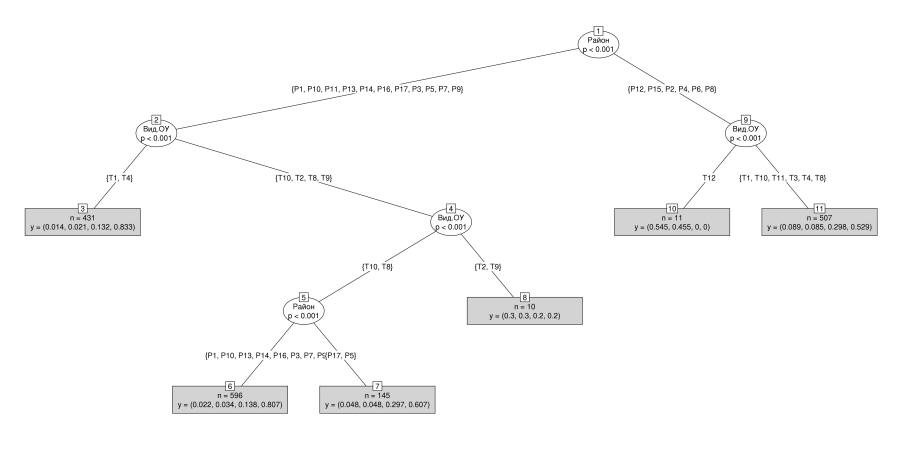
Любой доклад, статья требуют наличия выводов. Но в данном случае выводы делать слушателю/читателю. Мы же пытались заразить вас задором и смелостью, а также сделали попытку дать вам возможность полюбить аналитику так, как мы любим ее. И последнее: часто приходится слышать «нам так удобнее», «от нас требуют — мы даём», «у нас нет на это времени», «мы даём то, что от нас хотят увидеть». Это позиция, и эту позицию можно понять, но нельзя уважать, так как это позиция акта покупки-продажи, в которой участники торгуют заведомо плохим товаром.
Литература
1.
Thomas H. DavenportD.J. Patil. Data Scientist: The Sexiest Job of the 21st Century. OCTOBER 2012
2. Chris Morris. The Sexiest Job of the 21st Century: Data Analyst. 5 Jun 2013
3.
STEVE LOHR. For Today’s Graduate, Just One Word: Statistics August 5, 2009
4.
С.Э. Берестовицкая.
Школа как объект бюрократического насилия
5.
Мониторинг степени удовлетворённости участников
образовательного процесса различными сторонами жизнедеятельности
образовательного учреждения
6. Zuur, A. F., Ieno, E. N. and Elphick, C. S. (2010), A protocol for data exploration to avoid common statistical problems. Methods in Ecology and Evolution, 1: 3–14. doi: 10.1111/j.2041-210X.2009.00001.x
|
